
“在控制理论中,反馈是系统的灵魂。一个没有反馈的系统是‘开环’的,它无法感知偏差,更无法修正错误,最终必然走向发散与崩溃。” —— 诺伯特·维纳(控制论创始人)
序言:为什么你的勤奋在数学上注定失效?
在高效学习的领域,最隐蔽的陷阱不是“懒惰”,而是进入了“开环式勤奋”的状态。
大多数人的学习路径是一个开环系统(Open-loop System):输入信息 $\rightarrow$ 产生掌握的幻觉 $\rightarrow$ 停止。这种模式的致命缺陷在于:系统无法感知输出结果,更无法根据偏差进行自我修正。
如果你处于“开环”状态,你的进步将陷入“稳态误差”的死循环——你看过的书、刷过的题,由于没有反馈回流,无法在大脑中沉淀为神经元的熵减过程。
本文将利用第一性原理拆解反馈的本质,教你如何通过配置原子化目标(Set-point)与高频纠偏(Delta),将你的认知系统重构为精准收敛的进化引擎。
第一性原理拆解:打破“伪装的努力”
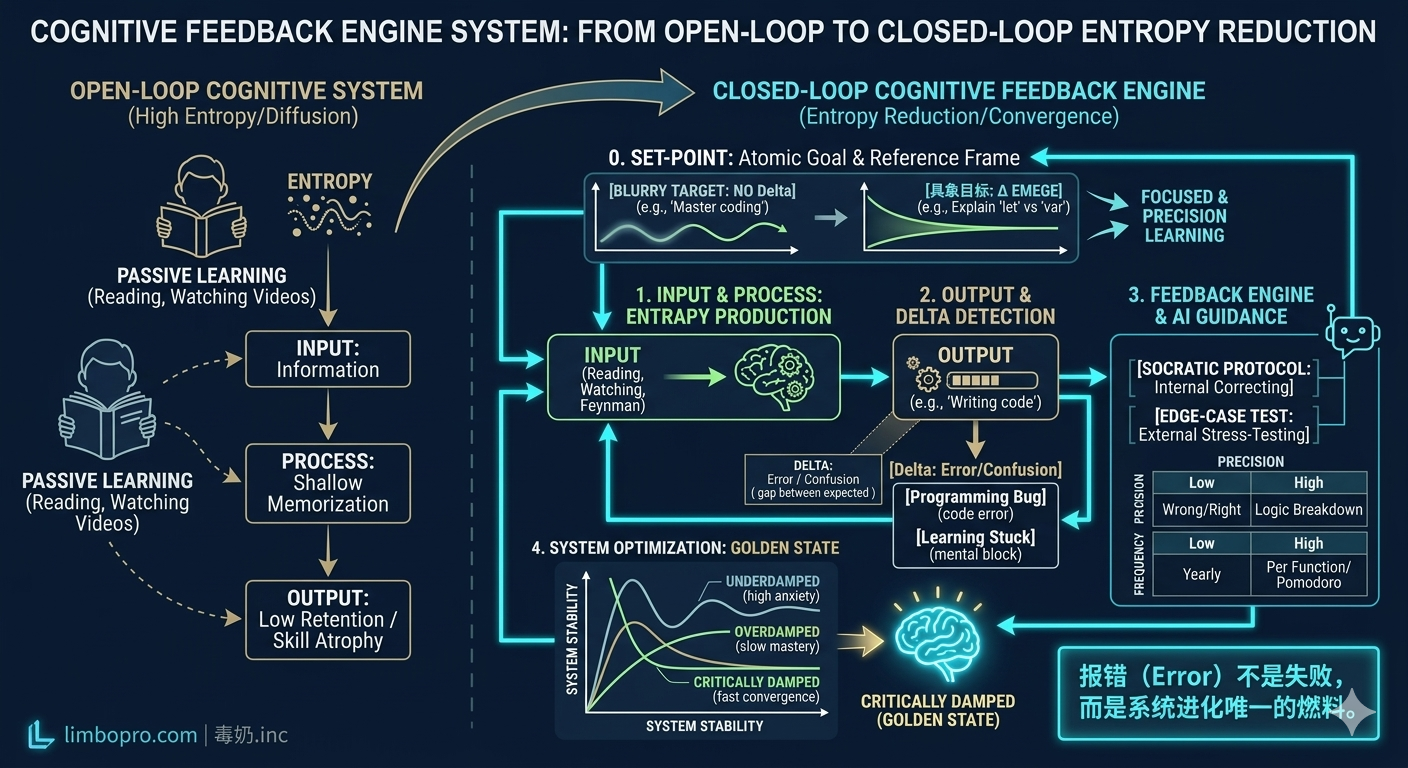
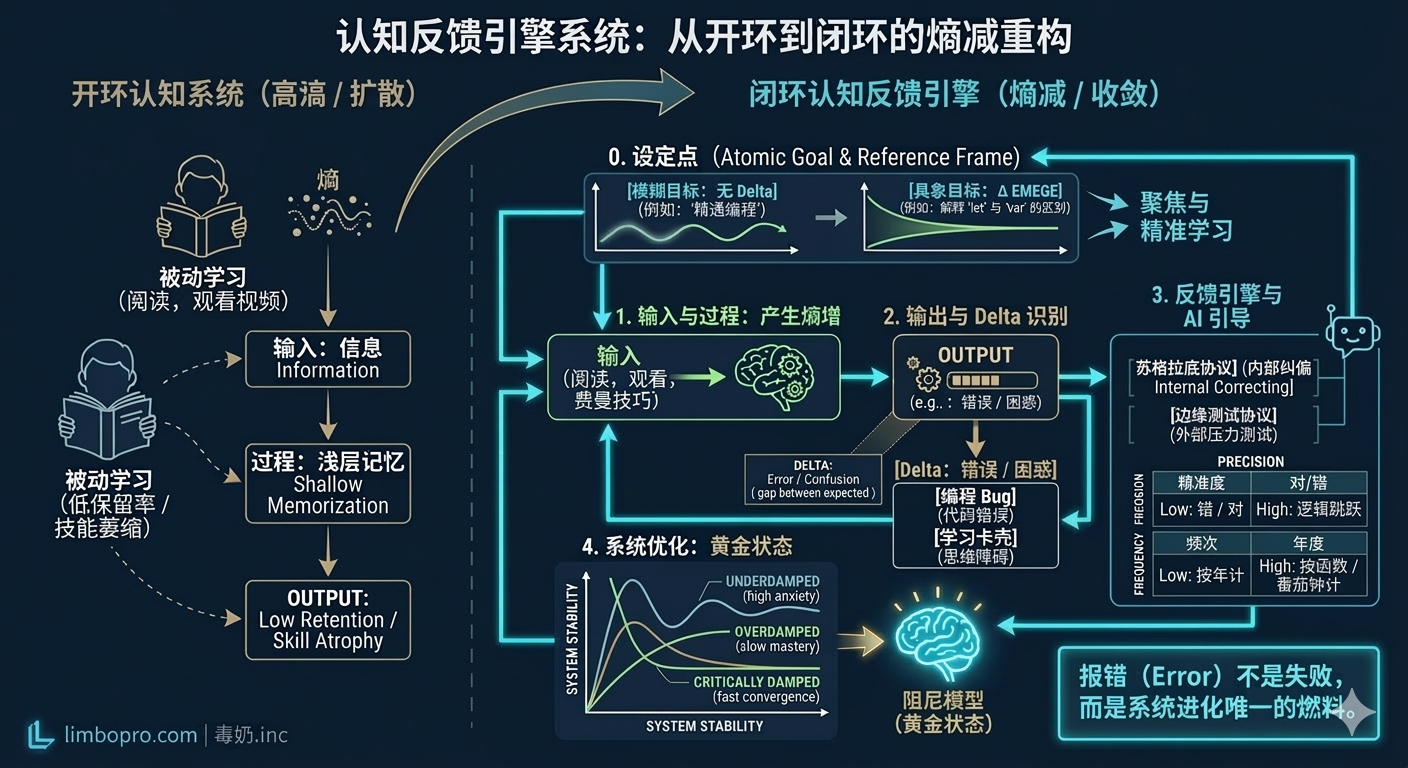
学习的本质不是信息的增量存储,而是神经元连接的熵减过程。
0. 设定值(Set-point):反馈的参照系
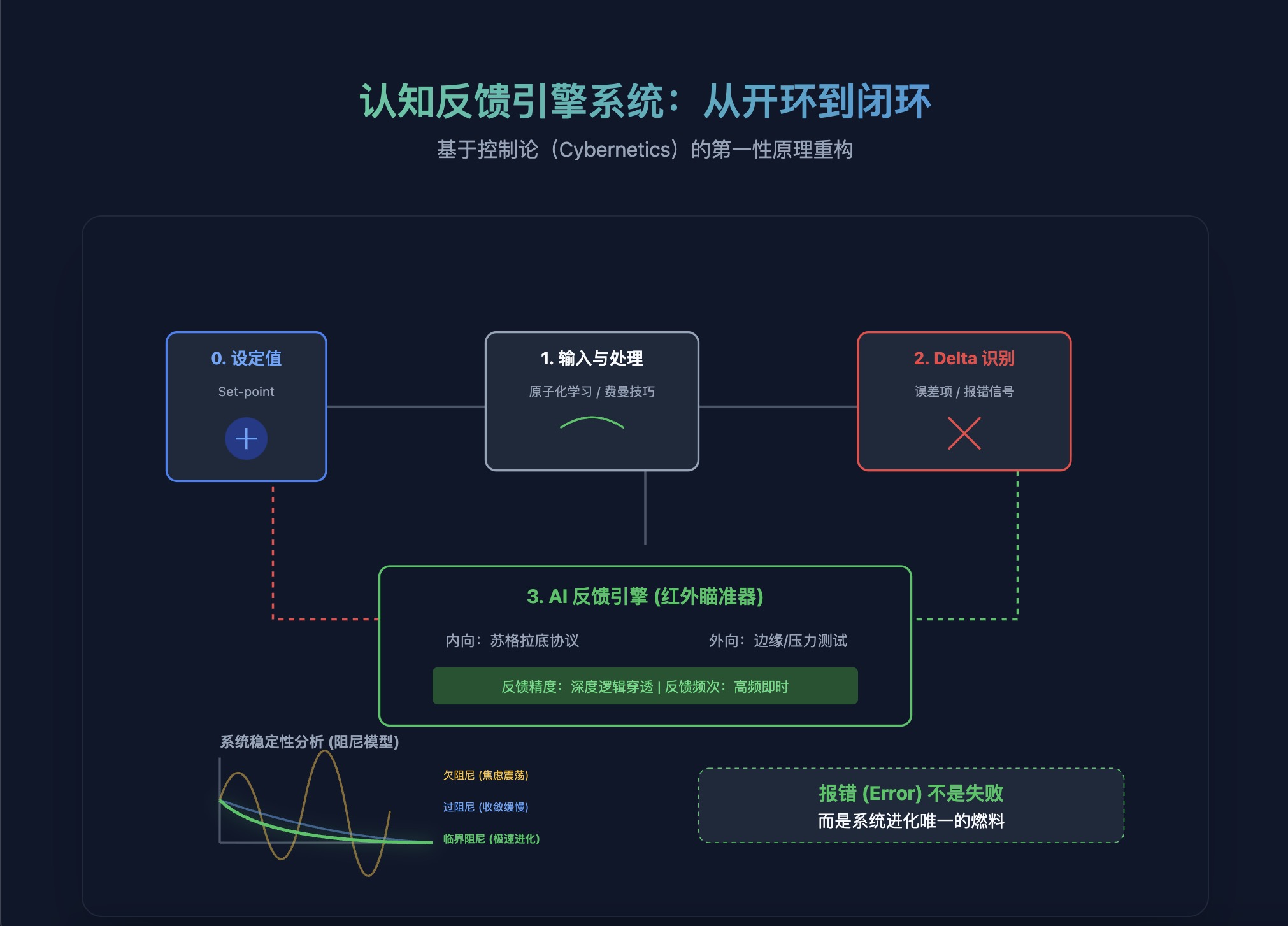
在控制理论中,反馈回路运作的前提是存在一个设定值(Set-point)。没有明确的目标,纠偏就失去了参照系,Delta(误差)也就无从谈起。
-
直觉映射:
- 模糊目标(无效反馈):“我要学好投资。”(系统无法计算 Delta,反馈器保持沉默,最终滑向开环)。
- 具象目标(有效反馈):“我能清晰解释‘贴现现金流模型’的三个核心变量。”(只要有一个细节说不清,Delta 立刻显现,引导你精准补课)。
-
第一性原理:目标必须原子化。目标拆解得越小,反馈的时钟周期就越短,系统进化的灵敏度就越高。
1. 从开环到闭环:进化的底层逻辑
- 开环学习(低效能):只有输入(Input),没有纠偏(Delta = ∞)。在这种模式下,大脑通过“熟悉感”伪造“掌握感”,产生致命的熟练度幻觉。
- 闭环学习(高复利):其逻辑链条为 [目标] → [输入] → [处理] → [输出] → [反馈/纠偏]。
- 误差项 ($\Delta$) 的决定性:学习速度不取决于你阅读的页数,而取决于大脑识别“预期”与“实测”之间差距的速度。反馈是让误差趋近于零的唯一路径。
本文系统架构:你的认知导航仪
在进入深度推演前,请先建立全局视野。本文将按以下路径重构你的学习系统:
- 底层逻辑:第一性原理拆解,定义反馈回路的逻辑起点——设定值(Set-point)。
- 核心参数:调优反馈系统的四大变量:目标、Delta、频次与精度。
- 回路构建:通过认知心理学与控制工程视角,将理论转化为具体行为(费曼技巧、最小闭环)。
- 引擎落地:将 AI 配置为红外瞄准器,利用苏格拉底等协议执行压力测试。
- 系统升维:引入控制论(Cybernetics),建立稳态与熵减的普适哲学。
优化反馈参数:目标、Delta、频次与精度
为了达到极致的学习速度,你需要动态调节反馈系统的四个核心参数。它们共同决定了你的认知系统是处于“失控发散”还是“快速收敛”的状态:
1. 设定值 (Set-point):反馈的“参照基准”
-
文章概念:这是反馈回路运作的逻辑起点。没有目标,系统就无法定义什么是“偏差”。
-
直觉映射:
- 模糊目标(无效):“我要学好投资。”(系统无法计算 Delta,反馈器保持沉默)。
- 原子化目标(有效):“我能清晰解释‘贴现现金流模型’的三个核心变量。”(只要有一个细节说不清,Delta 立刻显现)。
-
优化原则:目标必须原子化。 目标拆解得越小,反馈的灵敏度就越高,误差累积的风险就越低。
2. 误差项 ($\Delta$):你的“痛点”即是“坐标”
- 文章概念:$\Delta$ 是预期(Set-point)与实测(Output)之间的差距。
- 直觉映射:
- 编程领域:你预期 Redis 脚本运行后会重启,结果报了
Connection Refused。这个报错信息就是最精确的 Delta 信号。 - 学习领域:你以为看懂了“费曼技巧”,但在尝试向 AI 解释时卡壳了。“卡壳”那一瞬间,就是 Delta 显形的时刻。
- 编程领域:你预期 Redis 脚本运行后会重启,结果报了
3. 时钟周期 (Clock Cycle):反馈的“频次”
-
文章概念:缩短反馈回路,提高系统对误差的响应灵敏度。
-
直觉映射:
- 低频:一年看一次体检报告(发现问题已是晚期)。
- 高频:运动时戴着心率表,心率一过载立刻降速(实时进化)。
-
操作建议:学习初期,频次胜过强度。 不要等学完一整章再测试,每学完一个核心函数,立刻去控制台 Run 一下。
4. 反馈精度 (Precision):拒绝“模糊的正确”
-
文章概念:反馈信号必须深入逻辑底层,而非停留在对错表面。
-
直觉映射:
- 低精度反馈:减肥只看体重(不知道掉的是水还是脂肪)。
- 高精度反馈:监控体脂率、基础代谢和皮质醇。
-
AI 实践:不要问 AI “我写得对吗?”,要问 “我的逻辑链条中哪一步存在‘过度跳跃’?”。
为什么这个系统的置信度是“极高”?
-
物理层:阻尼分析(System Damping)
- 欠阻尼(反馈太迟):像考试前才发现啥都不会,产生焦虑震荡。
- 过阻尼(反馈太碎):像过度依赖答案,大脑失去了自主思考的张力。
- 临界阻尼(黄金反馈):系统以最快速度趋近目标而不产生震荡。闭环学习的目标,就是配置“临界阻尼”。
-
生物层:提取效应(Testing Effect)
- 阅读是“洒水”,提取是“开凿”。反馈强迫大脑进行信号重构,这是神经元连接发生物理性改变的唯一路径。
多视角推演:如何构建高质量反馈回路
在理解了“四大参数”后,我们需要解决实操问题:如何在复杂的认知任务中,亲手搭建一套具备“临界阻尼”的反馈回路?
1. 认知心理学:将“原子目标”转化为“主动提取”
- 推演:目标(Set-point)的达成不能靠被动输入,必须通过“提取效应”来激活。
- 构建行为:费曼技巧。 当你尝试向他人(或 AI)解释一个概念时,任何“卡壳”都是最真实的 Delta 信号。
- 逻辑挂钩:这解决了反馈精度问题——卡壳点即是逻辑断层点。
2. 控制工程:通过“分段测试”压低“时钟周期”
- 推演:反馈系统的稳定性取决于响应速度。 延迟反馈会导致认知震荡,甚至让你在错误的道路上跑得太远。
- 构建行为:最小闭环实践。 不要等看完一本书再测试,要每看完一个核心逻辑就进行 5 分钟的实战反馈。
- 逻辑挂钩:这解决了反馈频次问题——将长周期的“开环”拆解为无数微小的“闭环”。
3. 系统动力学:利用“外部冗余”消除“熟练度幻觉”
- 推演:系统内部往往无法感知自身的稳态误差,必须引入外部参照系。
- 构建行为:AI 影子教练。 利用 AI 的多维对标能力,从资深架构师或数学家的视角对你的产出进行“压力测试”。
- 逻辑挂钩:这为下文的 ## 使用 AI 作为反馈引擎 埋下了伏笔,完成了从“理论构建”到“工具落地”的过渡。
使用 AI 作为反馈引擎
“一个不进行尝试、不产生错误、不接收反馈的学习者,其认知系统在本质上是死寂的。” —— 卡尔·波普尔(科学哲学家)
🛡️ 心理映射:把“报错”看作系统的“临界阻尼”
很多人害怕 AI 指出错误,这在控制理论中其实是“系统震荡”。
欠阻尼(逃避反馈):你害怕被纠错,导致认知偏差不断放大,最终系统崩溃(考试挂科/投资爆仓)。
临界阻尼(主动反馈):把 AI 的拷问看作是系统的吸收器。它不是在否定你,而是在帮你吸收掉虚假掌握感的“震荡”,让你的认知曲线以最快速度趋于平稳。
核心信条:报错(Error)不是失败,而是系统进化唯一的“燃料”。
在“反馈真空”中学习,你就像是在黑屋子里射箭;配置 AI 导师的目标,就是为你安装一个实时红外瞄准器。这个工具包的核心在于将 AI 从“问答模式”切换为“压力测试模式”。
配置你的 24 小时 AI 反馈导师
要将 AI 转化为顶级导师,你需要的不仅仅是对话,而是一套系统提示词(System Prompts)。
1. “苏格拉底”反馈协议(用于深度内化)
适用场景:当你觉得自己“学懂了”,需要进行内向反馈时。
提示词配置:
“你现在是一名精通[特定领域]的苏格拉底式导师。不要直接回答我的问题,也不要告诉我答案。请针对我提供的理解,提出三个递进的、旨在暴露我逻辑漏洞的深度问题。如果我回答错误,请引导我通过第一性原理自己发现错误。”
2. “边缘测试”协议(用于实战演练)
适用场景:当你掌握了某个模型或代码,需要进行外向反馈时。
提示词配置:
“我刚刚学习了[概念/策略]。请为我设计 3 个极端的、复杂的边缘案例(Edge Cases)。这些案例必须包含干扰项,旨在测试我是否真正理解了该概念的边界条件,而不是仅仅记住了定义。”
三大高效反馈工具
1. 盲区扫描仪 (The Blind Spot Scanner)
- 操作方式:将你的学习笔记或文章大纲粘贴给 AI。
- 指令: “基于这份笔记,分析我最可能存在的认知偏差。请指出逻辑链条中‘跳跃’最大的地方,并要求我详细补充那一块的推导过程。”
- 反馈价值:通过第三方视角打破“熟练度幻觉”。
2. 预测误差计 (Prediction Error Gauge)
- 操作方式:在看答案或运行结果前,先向 AI 描述你的预测。
- 指令: “我要执行[操作/代码/投资策略],我的预期结果是[X],依据是[Y]。请先不要运行,根据我的逻辑判断:我的预测中有哪些潜在的统计学或逻辑性错误?”
- 反馈价值:在结果出来前强制进行脑力建模,放大反馈的冲击力。
3. 多维对标表 (Multi-dimensional Benchmarking)
- 操作方式:让 AI 模拟不同专家对你的产出进行点评。
- 指令: “请分别模拟[资深架构师]、[严谨的数学家]和[实战派投资者]的视角,对我目前的方案进行批判。重点指出哪些地方不够简洁、逻辑不闭环或不可落地。”
完整案例示范:从“内存陷阱”到“闭包自由”
1. 初始状态:开环执行(产生 Delta)
场景: 开发者希望通过循环创建一组按钮,点击每个按钮时弹出其对应的索引编号。
错误代码: JavaScript
for (var i = 0; i < 3; i++) {
setTimeout(() => {
console.log("当前索引是: " + i);
}, 100);
}现象(Delta 识别): 开发者预期输出 0, 1, 2,但控制台实际全部打印出 3。
本质问题: 开发者大脑中建立的是“快照模型”,而 JS 引擎执行的是“引用模型”。这种预期与实测的偏差就是 Delta。
2. 反馈阶段:启动“苏格拉底”协议(定位 Delta)
用户输入: “为什么我的循环只输出最后一位索引?我使用了 setTimeout。”
AI 的反馈(精准纠偏):
“请思考:当
setTimeout里的回调函数在 100ms 后真正执行时,外层的for循环是否已经结束?此时,变量
i是存储在每个函数自己的空间里,还是所有函数都共享同一个被修改后的i?”
开发者思考: “因为 var 没有块级作用域,循环结束时 i 变成了 3。异步回调执行时,它们去取 i 的值,只能取到最终的 3。我的逻辑断层在于对‘作用域生命周期’的误解。”
3. 修正阶段:梯度下降(消除 Delta)
开发者尝试修正 (v2 - 闭包手动闭环): 利用立即执行函数(IIFE)强行捕获快照。
JavaScript
for (var i = 0; i < 3; i++) {
(function(capturedI) {
setTimeout(() => {
console.log("当前索引是: " + capturedI);
}, 100);
})(i);
}开发者最终进化 (v3 - 现代语法闭环): 利用 let 的块级作用域,让引擎自动处理闭包。
JavaScript
for (let i = 0; i < 3; i++) { // let 在每次迭代都会创建一个新的绑定
setTimeout(() => {
console.log("当前索引是: " + i);
}, 100);
}4. 案例复盘:闭环学习的复利
| 环节 | 认知跳跃 | 系统状态 |
|---|---|---|
| Input | 编写 var 循环 |
开环:盲目信任直觉。 |
| Delta | 发现输出全为 3 | 触发:感知到系统偏离预期。 |
| Feedback | 理解作用域引用 | 纠偏:通过 AI 引导重构底层认知模型。 |
| Success | 掌握 let 与闭包本质 |
稳态:逻辑闭环,具备迁移处理复杂异步的能力。 |
批判性评估:AI 反馈的优势与劣势
| 维度 | 优势 (Pros) | 劣势/风险 (Cons) |
|---|---|---|
| 即时性 | 零延迟。 能够在产生疑问的瞬间获得反馈,强化神经连接。 | 幻觉风险。 AI 可能一本正经地提供错误的反馈(幻觉),需保持批判。 |
| 精确度 | 能在海量数据中精准捕捉逻辑矛盾。 | 缺乏情感维度。 无法感知学习者的心理疲劳,可能导致过度压力。 |
| 置信度 | 中高。 基于 LLM 的逻辑推理能力,能处理大部分结构化知识。 | 领域局限性。 在极尖端或高度主观的领域,反馈价值可能下降。 |
你的反馈工作流
- 学习 (Input):25 分钟番茄钟。
- 镜像 (Reflection):使用“苏格拉底协议”让 AI 拷问你。
- 纠偏 (Correction):根据 AI 指出的盲区重新查阅资料。
- 实战 (Output):使用“边缘测试协议”进行压力测试。
行动指南:TAGN 框架下的反馈工作流
- T (Target):选定一个具体概念。
- A (Analysis):向 AI 提供你的理解。
- G (Guidance):使用“苏格拉底协议”,让 AI 提出三个反直觉问题挑战你。
- N (Next Step):根据“卡壳”点,精准回溯原始文档。
结论与自我审核
- 核心命题:反馈是高效学习的第一要素,它将随机的输入转化为有向的进化。
- 置信度评级:高(基于控制理论及认知科学的海量证据)。
- 闭环检查:
- 是否使用了第一性原理?(是,拆解到了误差项 $Delta$)。
- 是否包含多视角?(是,包含心理学、工程学、行为学)。
- 逻辑是否闭环?(是,从本质到方法再到案例)。
建议行动计划:
在接下来的学习中,请强制自己每学习 25 分钟,就进行一次 5 分钟的“输出反馈”(如写出核心逻辑或完成一道习题)。不要怕错,报错正是系统进化的开始。
维度延伸:控制论(Cybernetics)的系统观
如果我们跳出“学习”这一单一行为,从第一性原理审视,反馈其实是控制论(Cybernetics)的底层语言。掌握控制论的思维方式,意味着你具备了从系统高度俯视复杂问题的能力。
1. 稳态(Homeostasis):系统生存的红线
- 本质: 系统在外界噪声干扰下保持核心变量稳定的能力。
- 推演: 学习系统的稳态不是“记住知识”,而是“逻辑闭环”。失去反馈的系统,其内部熵值会迅速增加,最终走向发散与崩溃。
2. 正负反馈的阴阳两极
- 负反馈(纠偏): 它是系统的刹车与免疫系统。通过不断识别 $\Delta$ 并取反,让系统回归目标。这是文章讨论的进化核心。
- 正反馈(爆发): 输出反过来加强输入。它是复利,也是雪崩。
- 共识: 卓越的学习系统需要负反馈来修正路径,正反馈来堆叠势能。
3. 艾什比定律(Ashby's Law):多样性吸收多样性
- 核心命题: “只有多样性才能吸收多样性。”(Only variety can destroy variety.)
- 推演: 面对高复杂度的 Bug 或市场波动(高多样性),单一的线性思维(低多样性)注定失效。
- 行动指南: 这正是我们需要“多视角推演”的原因。你脑中的跨学科模型越丰富,你应对现实世界扰动的“控制权”就越高。
置信度评级:极高。 控制论不仅是机器的科学,更是关于“目标、信息与反馈”的普适哲学。
核心术语深度拆解
针对文章中涉及的硬核术语,按照第一性原理进行拆解,以更通俗但保持严谨的方式补充解释。
1. 熵减 (Entropy Reduction)
-
本质: 熵是物理学中衡量“混乱程度”的度量。在一个孤立系统里,事物倾向于从有序走向无序(熵增)。
-
学习语境: 学习的过程就是通过投入能量(思考和反馈),将碎片化、无序的信息整合为高度有序的知识体系。熵减意味着你的大脑逻辑越来越清晰,知识的“有序度”在提高。
-
置信度评级: 高。
2. 开环 vs 闭环 (Open-loop vs Closed-loop)
-
本质: 源自控制工程。
- 开环: 像射箭,箭离弦后,你无法再控制它的路径。只有输入(射箭),没有修正。
- 闭环: 像导弹,在飞行中不断感应目标位置并修正轨道。有输入、有检测、有纠偏。
-
学习语境: 只读不练是“开环”,因为你不知道自己理解得对不对;边学边测、根据结果调整策略是“闭环”。
3. 第一性原理 (First Principles Thinking)
- 本质: 逻辑推演的起点。拒绝使用经验主义的“类比”,而是将事物拆解到最基本的真理(不可再拆分的基石),再从基石向上推导。
- 学习语境: 遇到难题时不看别人怎么做(模仿),而是问:“这个问题的本质物理/逻辑限制是什么?”从而找到最优解。
4. 梯度下降 (Gradient Descent)
- 本质: 数学优化算法。想象你在浓雾笼罩的山上,想下到山谷(最优解),你每走一步都感受脚下坡度最陡的方向,顺着坡往下走。
- 学习语境: 通过反馈发现理解偏差(坡度),每次修正一点点,最终逼近“完全掌握”的状态。
5. 误差项 (Delta / Δ)
- 本质: 目标值与实际值之间的差距。
- 学习语境: 它是反馈的灵魂。如果没有 Delta(即你觉得自己全懂了,没有发现错误),你的学习系统就会停滞。高效学习者不是在逃避错误,而是在主动寻找 Delta。
以上内容,在 Genimi 协助下完成。
版权属于:毒奶
联系我们:https://limbopro.com/6.html
毒奶搜索:https://limbopro.com/search.html
番号搜索:https://limbopro.com/btsearch.html
机场推荐:https://limbopro.com/865.html IEPL专线/100Gb/¥15/月起(最高享8折优惠)
毒奶导航:https://limbopro.com/daohang/index.html本文链接:https://limbopro.com/archives/35021.html · 镜像:https://limbopro.github.io/archives/35021.html
本文采用 CC BY-NC-SA 4.0 许可协议,转载或引用本文时请遵守许可协议,注明出处、不得用于商业用途!




